iPlantação
Participantes:
Rafael Munhoz Almeida da SilvaResumo do projeto:
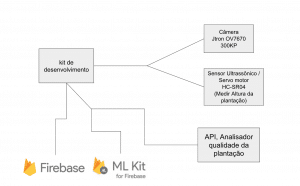
Redução de custos e aumento de confiabilidade na coleta de dados para plataforma de análise da qualidade da plantação de soja através da completa automatização do procedimento. Atualmente, esta plataforma se baseia na altura da plantação e na imagemDescrição do projeto:
Desenvolver uma solução que ficará distribuída no campo e se comunicará com a plataforma enviando periodicamente, ou sob demanda, a altura e a imagem da plantação de soja para que a plataforma faça o processamento e determine a qualidade da plantação de maneira a substituir a coleta manual.
A solução também deverá contemplar o desenvolvimento de um classificador que será desenvolvido utilizando o framework Tensor Flow do google. Este classificador será responsável por produzir um “score” da plantação de soja para cada porção da fazenda.
Histórico do desenvolvimento:
Problemas, Go Horse e final feliz
Olá pessoal do forum, vou tentar descrever aqui um pouco da nossa jornada durante esse mês de desenvolvimento, em primeiro lugar gostaria de agradecer muito o Rédi e o João por todo o apoio durante essa aventura.
Tentamos com esse projeto envolver todas as técnologias que estão na moda, tais como Machine Learning, Tensor Flow, Keras, Iot, Android, React, Firebase, Serveless, entre outras, de maneira a integrar todas de ponta a ponta e construir um protótipo de uma solução que faz uma foto de uma plantação, prepara os dados da foto para serem processados pelo modelo construído no TensorFlow e extrai como resultado um idicador que diz se a plantação está com uma qualidade boa ou ruim, esses dados são então enviados para uma conta do Firebase e exibidos em um frotend escrito em React.
Como já era esperado algumas dificuldades apareceram e mudanças na arquitetura e no escopo inicial foram feitas, veja na sequencia o nosso drama:
O problema da camera escura
Na proposta inicial tinhamos definido que iriamos utilizar a camera ov7670, pois eu tinha uma sobrando em casa de um outro projeto que quase dominou o mundo, só que não. Voltemos ao nosso problema então, o que aconteceu foi que prontamente tantamos conectar a ov7670 diretamente na GPIO da 410 C porém a única imagem que viamos era uma imagem escura e mais nada, o que fazer então, novamente seguindo o método Go Horse e utilizando o que tinhamos em mãos partimos para o uso de um Raspberry com a sua camera, a ideia era então produzir as fotos com o Rasp e enviar essa foto para a placa 410C por bluetooth e funcionou !!!! todo mundo para o bar da esquina comemorar.
O problema do tempo
Seguindo a proposta inicial iriamos utilizar um sensor ultrasonico e um motor de passo e muita trigonometria para medir a altura média da plantação, como perdemos muito tempo tentando fazer a camera ov7670 funcionar desistimos dessa parte e até que não ficou ruim pois conseguimos bons resultados de acurácia apenas analisando a imagem da plantação no momento do treinamento da rede neural.
Com os “workarounds” feitos acima finalizamos a implementação do projeto baseado na arquitetura descrita no diagrama abaixo:
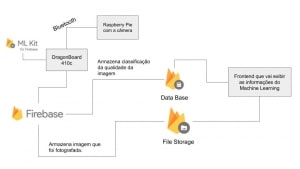
Descrição do funcionamento básico do protótipo
A cada intervalo de tempo definido pelo usuário o Raspberry produz uma foto no formato de paisagem da plantação onde ele está posicionado. Esta imagem é então transferida para a placa DragonBoard 410C via bluetooth e em seguida tratada por um algoritmo que quebra essa imagem em várias outras de menor dimensão, no caso usamos 15 x 15 pixels, para fazer esse tratamento utilizamos uma versão da biblioteca OpenCV para a plataforma Android.
Teremos como resultado deste projeto o input para o algoritmo de Machine Learning, que foi previamente construido e treinado utilizando-se as ferramentas Keras e TensorFlow, para rodarmos esse algoritmo localmente na DragonBoard, foi necessária uma conversão do Tensor Flow para o Tensor Flow Light, que é mais leve e foi especialmente desenvolvido para em dispositivos móveis.
Como saída do modelo do Tensor Flow Light teremos para cada “tile”, ou seja para cada pedaço de 15 x 15 pixels, teremos entre 0 e 1 que indicará qual a qualidade daquele pedacinho da imagem, quanto mais próximo de 1 melhor a qualidade e quanto mais próximo de 0 pior a qualidade.
Por fim calculamos a média de qualidade levando em consideração todos os tiles e enviamos esses dados junto com a imagem que foi produzida para o Firebase. Estes dados então serão visualizados por um aplicativo web escrito em React.
Hardware:
Software/Firmware:
Machine Learning
Tinhamos a nossa disposição um conjunto de dados com 610 imagens já classificadas pelo engenheiro agronomo, para cada uma das imagens foi dado um valor entre 1 e 5 onde 1 era muito ruim e 5 era muito bom, o primeiro desafio aqui foi pensar em um descritor para a imagem, por simplicidade optamos por consturir o descritor baseado no RGB da imagem, então fizemos o seguinte, calculamos a média de todos os valores de Red, de Green e de Blue da imagem, nosso vetor de entrada ficaria então com dimensão pequena o que favoreceria a execução do treinamento da rede. Nesse ponto ainda não tinhamos decidido se iriamos usar o Tensor Flow ou o scikit-learn, e neste momento optamos por usar o scikit-learn, veja abaixo um pedaço do código que constroi esse descritor:
def __create_feature_vector_mean(self, file_name, piquete_id, score, height):
rgb_mean = [0] * 3
image_path = self.__image_files_root_folder+ str(piquete_id)+'/'+file_name
image = cv2.imread(image_path)
print(image_path)
means = cv2.mean(image)
if means is not None:
#raw = image.flatten()
print(str(means[:3])+'\n')
rgb_mean[0] = means[0]
rgb_mean[1] = means[1]
rgb_mean[2] = means[2]
#rgb_mean[3] = height * 1000
#print(preprocessing.scale(rgb_mean))
#means[3] = height
#scaled_means = preprocessing.scale(means[:3])
if self.__check_for_bad_images(file_name, piquete_id, score):
self.__farm_dataset.feature_vector.append(preprocessing.scale(rgb_mean))
#self.__farm_dataset.feature_vector.append(preprocessing.scale(means))
return True
else:
return False
else:
return False
Com esse descritor implementado partimos para a execução do treinamento do algoritmo utilizando o scikit-learn, fizemos isso neste momento pois a curva de aprendizado do scikit-learn é mais rápida que a do Tensor Flow, neste instante ainda estavamos considerando este problema com um problema do tipo multiclasse, pois como dito anteriormente nossa classificação foi baseada em valores de 1 a 5, veja abaixo o código que implementa o treinamento do algoritmo no scikit-learn
def runCrossValidation(self, farm_dataset):
print('start cross validation')
x_train, x_test, y_train, y_test = cross_validation.train_test_split(
farm_dataset.feature_vector,farm_dataset.target, test_size=0.15)
#x_train_scaled = preprocessing.scale(x_train)
#y_train_scaled = preprocessing.scale(y_train)
#x_test_scaled = preprocessing.scale(x_test)
#y_test_scaled = preprocessing.scale(y_test)
print('end cross validation ')
print('start grid search')
rfc_parameters = { 'n_estimators': [200, 700], 'max_features': ['auto', 'sqrt', 'log2'] }
rfc_parameters_2 = {'bootstrap': [True, False], 'max_depth': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, None],
'max_features': ['auto', 'sqrt'],'min_samples_leaf': [1, 2, 4],'min_samples_split': [2, 5, 10],
'n_estimators': [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]}
parameters = {'kernel': ['rbf'], 'C': [1, 10, 100, 1000, 10000],
'gamma': [0.01, 0.001, 0.0001, 0.00001]}
clf = grid_search.RandomizedSearchCV(RandomForestClassifier(), rfc_parameters_2, n_iter = 10, cv = 3, verbose=5, random_state=42, n_jobs = -1).fit(x_train, y_train)
#clf = grid_search.GridSearchCV(RandomForestClassifier(), rfc_parameters_2, verbose = 5).fit(x_train, y_train)
#clf = grid_search.RandomizedSearchCV(RandomForestClassifier(), rfc_parameters, verbose = 5).fit(x_train, y_train)
#clf = grid_search.GridSearchCV(svm.SVC(), parameters, verbose = 5).fit(x_train, y_train)
#clf = grid_search.RandomizedSearchCV(svm.SVC(), parameters, verbose = 5).fit(x_train, y_train)
print('end grid search')
self.__classifier = clf.best_estimator_
print()
print('Parameters:', clf.best_params_)
print()
print('Best classifier score')
predicted = self.__classifier.predict(x_test)
print(metrics.classification_report(y_test,predicted))
print(predicted)
print(y_test)
print(accuracy_score(y_test,predicted))
Com o descritor e o algoritmo escolhido, que no caso foi o RandomForest, começamos a rodar o treinamento, e percebemos que os resultados de acurácia ficavam entre 50% e 60% ocilando muito. Resolvemos então partir para o Tensor Flow, utilizando o Keras. O Keras simplifica em muito o uso do Tensor Flow, pois com ele podemos construir a rede que será treinada de maneira mais simples, sem ter que aprender todos os detalhes do Tensor Flow.
Porém resolvemos modificar o descritor também, tivemos a idéia de fatiar a imagem original em “tiles”, retangulos de 15 x 15 pixels, desta maneira conseguiriamos mais amostras pois de uma imagem de dimensão 1000 x 750 conseguiriamos até 3250 pequenos retângulos de 15 x 15 pixels. Veja abaixo um trecho da implementação deste descritor:
def __create_feature_vector_raw(self, file_name, piquete_id, score, flatten=False):
sample_size = (self.CROP_WIDTH, self.CROP_HEIGHT, 3)
image_path = self.__image_files_root_folder+ str(piquete_id)+'/'+file_name
print(image_path)
image_raw = cv2.imread(image_path)
if image_raw is not None:
if not self.__check_for_bad_images(file_name, piquete_id, score):
return (False ,0)
cropped_images = []
image_square_counter = 0
image_raw_width = image_raw.shape[0]
image_raw_height = image_raw.shape[1]
print(image_raw_height)
print(image_raw_width)
square_qtd_x = int(image_raw_width / sample_size[0])
square_qtd_y = int(image_raw_height / sample_size[1])
print(square_qtd_x)
print(square_qtd_y)
for sq_indx_x in range(square_qtd_x - 2, square_qtd_x):
for sq_indx_y in range(0, square_qtd_y):
cropped_images.append(np.zeros(sample_size, np.uint8))
for i in range(0, sample_size[0]):
for j in range(0, sample_size[1]):
cropped_images[image_square_counter][i][j] = image_raw[i + sq_indx_x * sample_size[0]][j + sq_indx_y * sample_size[1]]
image_square_counter = image_square_counter + 1
print(' ******* Squares counter ******** '+str(image_square_counter))
print(' ******* Cropped image size ***** '+str(len(cropped_images)))
for img_index in range(0, len(cropped_images)):
if flatten:
expanded = np.array(cropped_images[img_index])
self.__farm_dataset.feature_vector.append(expanded.flatten())
else:
self.__farm_dataset.feature_vector.append(cropped_images[img_index])
return (True, image_square_counter)
else:
return (False, 0)
Com esse descritor melhorado,definimos a rede neural da seguinte maneira:
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.40)) #0.4 removed as it is bad of tflite # 0.25
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.25)) #0.25 removed as it is bad of tflite # 0.5
model.add(Dense(num_classes, activation='sigmoid')) #sigmoid
model.compile(loss=keras.losses.binary_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
filepath="weights-improvement-{epoch:02d}-{val_acc:.2f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1, save_best_only=True, mode='max', period=5)
callbacks_list = [checkpoint]
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
callbacks=callbacks_list,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=5)
Agora utilizando o novo descritor e com o Tensor Flow conseguimos chegar na marca dos 73% de acurácia e a ocilação caiu para próximo de 0%. Durante todo esse processo descobrimos várias inconsistências nos dados, como no caso de encontrarmos uma mesma imagem com com classificações diferentes, dos 610 exemplos que tinhamos 110 estavam com problema. Além disso notamos que o dataset estava desbalanceado, para resolver o desbalanceamento, decidimos reduzir o problema a duas classes, uma que seria caracterizada como boa e outra como ruim. Veja abaixo a saída da melhor geração de treinamento
Epoch 29/40 22975/22975 [==============================] - 107s 5ms/step - loss: 0.2406 - acc: 0.8859 - val_loss: 0.8012 - val_acc: 0.7329